《Clojure数据分析秘笈》——1.8节从网页表中抓取数据
本文共 702 字,大约阅读时间需要 2 分钟。
本节书摘来自华章社区《Clojure数据分析秘笈》一书中的第1章,第1.8节从网页表中抓取数据,作者(美)Eric Rochester,更多章节内容可以访问云栖社区“华章社区”公众号查看
1.8 从网页表中抓取数据
互联网上数据无处不在。遗憾的是,许多互联网上的数据不易获得。这些数据深埋于表、文章或者深层嵌套的标签中。网络抓取是一件让人讨厌的体力活,但是它通常又是唯一能将这些数据取出用于分析的手段。本方法描述如何加载网页并挖掘其内容以便取出数据。使用Enlive库()可以完成这项工作。这个库使用基于CSS选择器的领域专用语言(Domain-Sepecific Language,DSL)在网页中定位元素。这个库也可用于模板。在本例中,仅使用它从网页中取出数据。1.8.1 准备工作
首先,需要将Enlive添加到项目的依赖中: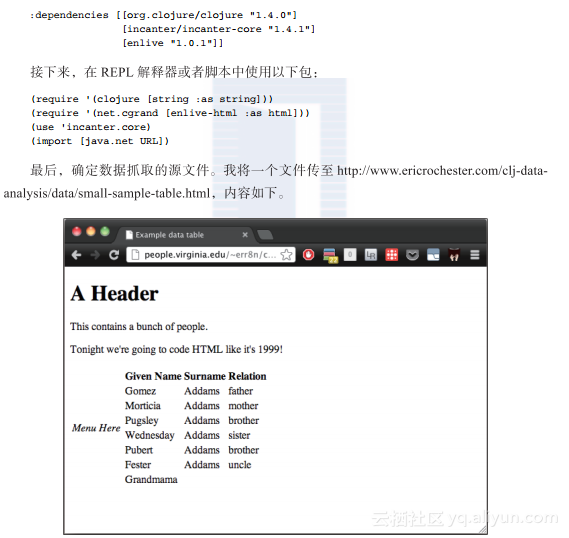
有意地去掉文件的其他内容,并使用表的布局。
1.8.2 具体实现- 由于任务稍有些复杂,这里将每步的工作写成函数。

现在,选择所有表头单元,抽取其中的文本,将每个转换为关键词,然后将整个序列装入向量。得到了数据集的头部:

需要注意的是,在此展示的代码是多次试错后的结果。屏幕抓取的过程是这样的。通常我将下载并保存页面,从而不需要持续向Web服务器发送请求。然后启动REPL并在其中解析网页。可以通过浏览器的“查看源代码”功能查看网页和HTML,并且可以在REPL解释器中交互式地检查网页中的数据。由于比较方便,在工作过程中,我可以不断地在REPL解释器和文本编辑器中复制、粘贴代码。这种工作流程和环境使得屏幕抓取这样一个即使一切正常都需要精细操作的困难任务变得很轻松。
转载地址:http://kecpa.baihongyu.com/
你可能感兴趣的文章
Java 关于finally、static
查看>>
Posix mq和SystemV mq区别
查看>>
P6 EPPM Manual Installation Guide (Oracle Database)
查看>>
XMPP协议、IM、客户端互联详解
查看>>
PHP写文件函数
查看>>
mysql的sql_mode合理设置
查看>>
函数连续性与可导性
查看>>
linux下libevent安装
查看>>
用ip来获得用户所在地区信息
查看>>
卡尔曼滤波
查看>>
linux下面覆盖文件,如何实现直接覆盖,不提示
查看>>
CSS3阴影 box-shadow的使用和技巧总结
查看>>
Linux下高cpu解决方案
查看>>
SQL事务用法begin tran,commit tran和rollback tran的用法
查看>>
centos7 crontab笔记
查看>>
.Net AppDomain.CurrentDomain.AppendPrivatePath(@"Libs");
查看>>
【Unity3D基础教程】给初学者看的Unity教程(零):如何学习Unity3D
查看>>
Android Mina框架的学习笔记
查看>>
合并两个排序的链表
查看>>
rtf格式的一些说明,转载的
查看>>